4 out of 8 following enhancements were privately requested by our customers, and we thank them for helping make StresStimulus a better performance tool.
1. Expanding extractor scope to parse response headers. Previously, the Text Delimited and the Regular Expression extractors could only be used to extract values from the response body. In this release, the scope of the extractors is expended to parse headers as well. There is no change in the UI. StresStimulus will automatically apply the same parsing rules not only to the response body but also to its header.
2. Form Field Extractors. The Field Extractor is a new type of extractor that can return a value of any html input field. It is easier to use than Text Delimited or Regular Expressions extractors. To define the Form Field Extractor, simply select the field name from the drop-down.
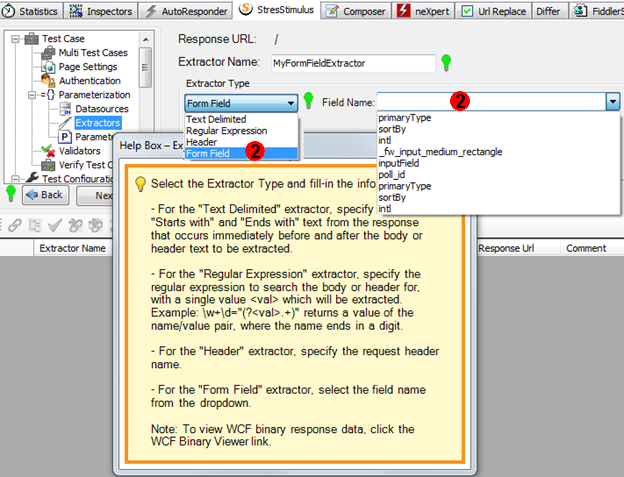
3. Header Extractor. The Header Extractor is a new type of extractor that can return a value of any response header. While the Text Delimited and the Regular Expression extractors can also be used to parse header (see the item 1 above), the Header Extractor is easy to use. To define the Header Extractor, simply select the field name from the drop-down (similar to the Form Field Extractor).
4. Parameterizing URL. Previously only the RESTful URL without a query string could be parameterized. In URLs with a query string, only the query string could be parameterized, not the entire URL.
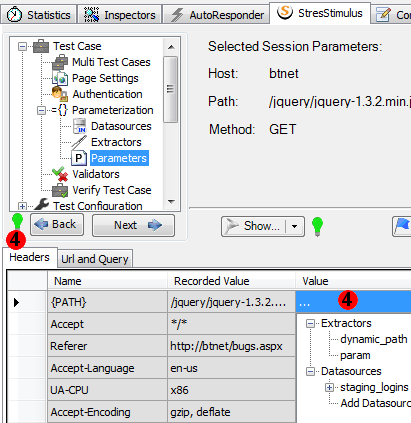
In this release the entire URL (GET or POST, with or without query string) can be parameterize using a new pseudo header called {PATH} located under the Header tab. To do so, right-click in the Value column of the URL row and in the Parameterization Control select desired extractor or data source field.
5. More granular error reporting. Previously, intrinsic HTTP errors took precedence over the customer validator's in the StresStimulus validation engine. As a result, custom validators had no effect on any HTTP 400 or 500 responses. Because of that, it was difficult to distinguish, for example, different HTTP 500 responses with different HTML bodies.
In this version, validators take precedence over the intrinsic HTTP errors. This allows defining different custom validators to recognize different errors in responses with the same http error code. For example, one custom validator will recognize a database error message, and another one will recognize a web server error message. As a result, the error report with http 500 errors will be more informative. There is no change in the UI. The benefit of this enhancement is that a user can make error reporting as granular as necessary.
6. More warnings are recognized by the Test Case Verification Engine. When the Test Case Verification Engine compares replayed and recorded sessions, it captures more conditions that may (or may not) expose some test configuration errors. For example, user will be informed if the replayed 302 redirect URL is different from the recorded 302 redirect URL.
7. Graph images include the legend. When copying and pasting the graph image, the legend is now embedded within the image. This is useful when creating your own custom performance reports, because the graphs now can be interpreted independently from the complete StresStimulus report.
The following three features where added in the previous release but were not documented. So their brief description is added hereby:
8. More test case mixing models. Previously, the test case mixing model was not configurable and it was based on probabilities. Every virtual user was randomly assigned to one of the test cases using probabilities proportionate to the test case mix weight.
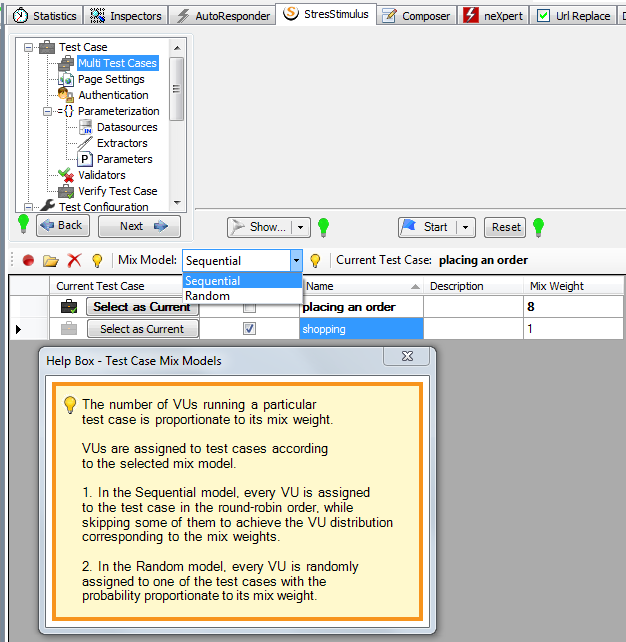
The option to select a test case mixing model is added. One more mixing model is added as well. The previous model is called “Random” and the new model is called “Sequential”. In the Sequential model, every VU is assigned to the test case in a round-robin order, while skipping some of them to provide that the resulting number of VUs in each test case is proportionate to its mix weights. This model will assure that each VU will run a different test case, and all test cases will be executed.
Update. In v 2.5 the Random mixing model is removed due to its limited use and to simplify UI. More useful test case mixing models will be added in the future.
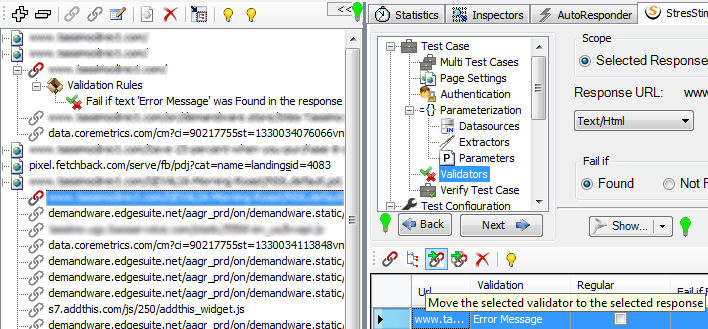
9. Moving/Cloning validators. A validator created for one response can be cloned or moved to a different response. To do so, in the Validators grid select a validator and in the Test Case Tree select a destination session. Then click the Move or Clone button in the Validators toolbar.
10. More complete previous results. In the initial 2.0 release, when a pervious tests result is loaded, the Key Indicators and Performance Counters graphs were restored. However, the data in the grids below the graphs were not restored. In the current version the data in these grids is restored as well. Besides that, unlike before, the restored graphs can be zoomed.
To navigate to other parts of the v2.0 notes, click the links below:
Previous Posts:
V2.0 beta is available for download here.