Need help with StresStimulus? Start here.
How to avoid duplicates when using dataset?
|
Unregistered User Posts: 514
4/14/2021
|
I was getting in touch as our team may have found a potential bug. Can SS confirm whether they are seeing the same issue please? Below are the details:
Details:
- Vusers: 30
- Dataset entries: 210
- Limit Dataset: Yes and “0”, i.e. all of the data was available to each VU.
- In our recent performance tests we have set “How to count iterations” to “Per VU”. This has shown the VUs, picking unique data from the dataset with each iteration.
- However, we recently changed the setting to the below. In theory, we assumed by choosing this option we wouldn’t need to calculate the number of “Max Iterations” per VU. Because we would simply enter the total number of iterations the all vusers should complete.
- What we discovered when selecting this option is the first 15 VUs would select unique rows data from the dataset, however, after that point the next VU seemed to pick the first row from the dataset. This caused duplicate orders to be created with the same subject details.
- By the end of test this setting achieved the goal of completed the Max Iterations set. However, during the process it ended up creating duplicate orders.
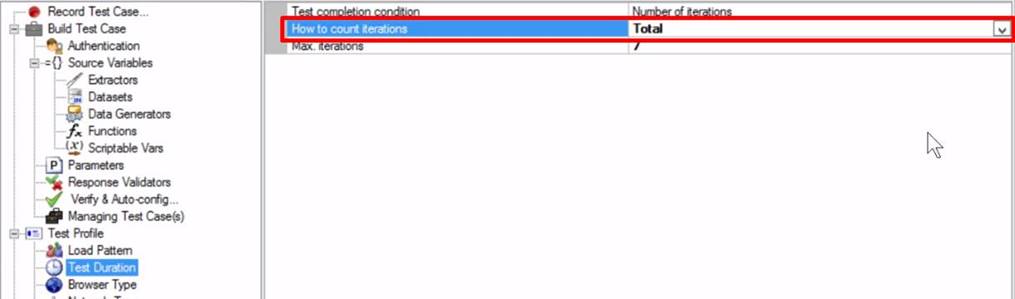
Can SS confirm whether our assumption on how this option works is correct?
|
|
|
0
link
|
Copyright © 2026 Stimulus Technology